When packaging any app in a Docker image, you run into the issue of how to protect the secrets, like database credentials or API keys.
We all know about not checking in secrets to Github (don’t we?), but we also don’t want to package secrets in the image. Anyone who can get at the image can also get at the secrets, and since the image proliferates through CI/CD pipeline and image repo, it’s near impossible to limit access effectively.
What we found to work best is to store secrets in a well protected Cloud Storage bucket, and have the app download the secrets on startup. This decouples the secrets from Docker images, and rotating secrets becomes a cinch.
The example here from an app written to run on Google Cloud Platform.
Layering Secrets in Flask
Flask gives you multiple ways to load configuration. Every time it loads a configuration, it overlays the existing configuration.
We can use the default settings (i.e., dev settings or reasonable defaults) in the code, then download and merge secrets.
Here we download secrets from a Cloud Storage bucket. The bucket should be restricted to allow read access from a specific service account assigned to the app.
As a paranoid implementation, you can encrypt the secrets in the bucket. The app decrypts the downloaded secrets then loads it in. Both encrypted and decrypted files get deleted. The app needs permission for the bucket as well as the crypto keyring in KMS.
You need to encrypt the secret file before uploading to the bucket. The shell script below encrypts and uploads a secrets.cfg file. To run this script, you need access to KMS keyring as well as write permission for the vault bucket
#!/usr/bin/env bash
gcloud services enable cloudkms.googleapis.com
KEYRING=keyring
KEY=secrets
gcloud kms keys list --location global --keyring $KEYRING
if [[ $? -ne 0 ]]; then
gcloud kms keyrings create ${KEYRING} --location global
gcloud kms keys create ${KEY} --location global \
--keyring ${KEYRING} --purpose encryption
fi
rm -f secrets.cfg.encrypted
gcloud kms encrypt --location global \
--keyring ${KEYRING} \
--key ${KEY} \
--plaintext-file secrets.cfg \
--ciphertext-file secrets.cfg.encrypted
gsutil cp sectets.cfg.encrypted gs://vault
Flask + Gunicorn Caveat
When running a Flask app under gunicorn, loading configuration file using relative path (i.e. app.config.from_pyfile('config/default_settings.py')) can fail. This is because gunicorn doesn’t change to the app directory. You need to supply--chdir flag to make gunicorn change to the directory that app expects.
Any sizable cloud infrastructure maintained manually is usually a mess.
What I’ve seen happen is this: A developer manually sets up an instance or two to get his/her project going. He/she manually set up firewall rules (security group on AWS) and subnets to go with this.
Then someone else comes along and brings up some other instances, and adds some other subnets and firewall rules.
Once this goes on a few times, you have lots of firewall rules and subnet configurations. If you let this go on, this grows to the point where you have a big mess that no one knows how anything is connected to what.
Quite often, everyone is too scared of touching anything because it might break something. So we keep inserting compute/DB instances and subnets and firewall rules making matters worse.
How do I know all this? Well, because I’m often that guy who set things up by hand in the very beginning. The cliché, of course, is I’ll just get by for now, we can do it right later.
Guilty as charged, but I’m sure you’ve been there too, no?
Start Off Right
So how do we I avoid ending up with this mess?
The root cause is that the initial setup is not automated and you start off creating instances by hand.
We all know DevOps automation is a tremendous help in maintaining Cloud infrastructure. You really need to start off using automation from the start. It really isn’t that hard.
We all area lazy creatures, but if we make this so it’s easier to just add a few lines of code to automation script than to futz with the cloud console UI, we probably will do the right thing.
So I wrote a simple set of TerraForm scripts to bootstrap a generic environment, so no manual setup is ever needed.
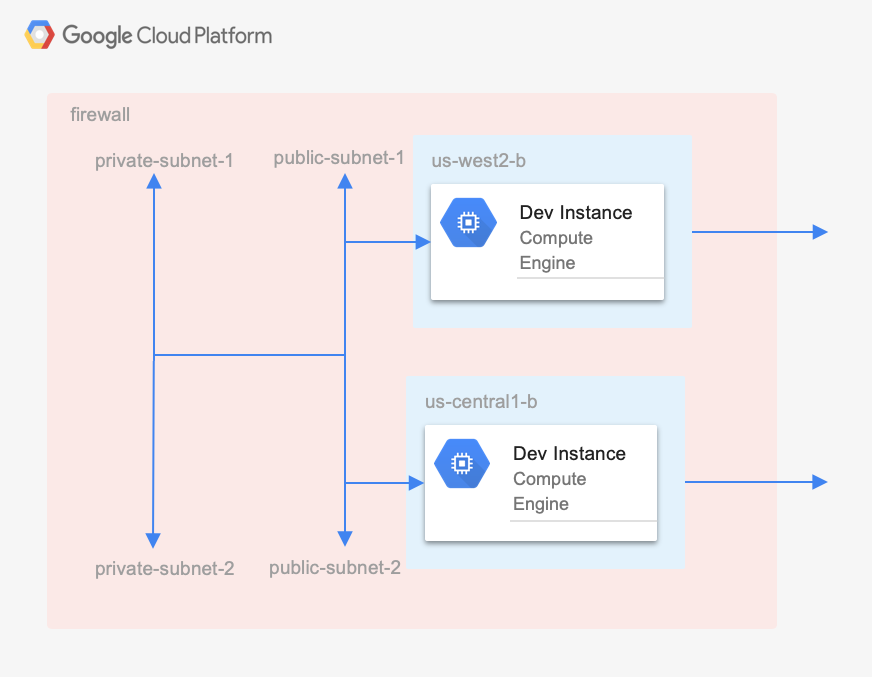
What follows is an example using TerraForm on Google Cloud Platform. In the example below, we bootstrap a multi-region network (VPC) with public/private subnets and instances.
Creating Environment
The example creates a standalone environment that contains the following on Google Cloud Platform:
A VPC Network
Two public subnets, one in region 1 and another in region 2
Two private subnets, one in region 1 and another in region 2
A firewall rule to allow traffic between all subnets
Firewall rules to allow ssh and http
A compute instance-1 in region 1 on public-subnet-1
A compute instance-1 in region 2 on public-subnet-2
TerraForm Scripts
Pre-requisite
In order to run the TerraForm scripts, you need Google Cloud Platform account, and TerraForm and Google Cloud SDK installed. There are many tutorials on this so I won’t go into it here.
You also need a service account with proper permission and its credentials downloaded locally. The credential file is referred to in main.tf.
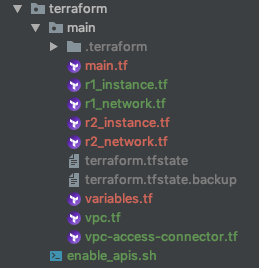
Directory Organization
To make things easier, TerraForm scripts are separated into:
main.tf – loads TerraForm configuration providers for GCP
variables.tf – defines variables used by scripts
main.tf – loads TerraForm configuration providers for GCP
vpc.tf – Defines VPC and firewall rules
r1_network.tf – Defines the subnets for region 1
r2_network.tf – Defines the subnets for region 2
r1_instance.tf – Defines the instance to start in region 1
r2_instance.tf – Defines the instance to start in regoin 2
TerraForm scripts
main.tf
We define two providers for GCP. A lot of features Google Cloud SDK are made available while in beta. This requires us to define the beta provider in order to access these beta features.
The credential is for the service account that is allowed to create/delete the compute resources in the GCP project.
As you most likely already know, with GCP you can create multiple VPC networks within a project. If you are coming from AWS, this looks the same at first, but there is a big difference. VPC network is global on GCP where VPC is regional on AWS.
This means your environment is multi-regional from the very beginning on GCP. To place resources in multiple regions, you need to create subnets in each region. All subnets route to each other globally by default, all you have to do is create subnets in regions of your choice. (As a side note, each project comes with a default network that covers every GCP region.)
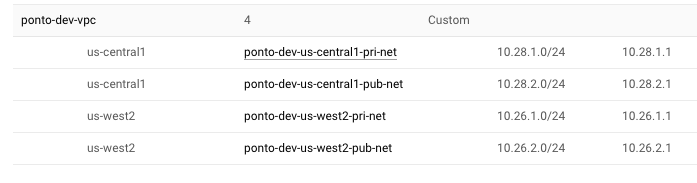
In this example, we create two networks (private/public) in two regions (r1/r2). Regions are defined in variables.tf.
The idea here is to attach private instances (with no public IP address) to private subnet, while public instances are assigned to the public subnet.
This is one area where we often see manual configurations get out of hand because intended network topology isn’t always followed. Having these subnets and instances defined in the Terraform script makes it far easier to maintain this.
resource "google_compute_subnetwork" "public_subnet_r1" {
name = "${format("%s","${var.company}-${var.env}-${var.region1}-pub-net")}"
ip_cidr_range = "${var.r1_public_subnet}"
network = "${google_compute_network.vpc.name}"
region = "${var.region1}"
}
resource "google_compute_subnetwork" "private_subnet_r1" {
name = "${format("%s","${var.company}-${var.env}-${var.region1}-pri-net")}"
ip_cidr_range = "${var.r1_private_subnet}"
network = "${google_compute_network.vpc.name}"
region = "${var.region1}"
}
r1_instance.tf
A compute instance is brought up in each region, and Nginx is installed. These instances are handy when developing TerraForm script. We can log into these instances to test the network configuration, and also these instances can serve as boilerplate code for creating more instances. GCP does give you a pretty good indication of applied firewall rules in the console, so you can do away with these instances as well.
Once the TerraForm scripts are in place, bringing up the environment is easy:
$> terraform init
$> terraform apply
This also executes really fast on GCP. It took mere just 70s…!
Once created, you can see in the console that two sets of subnets are created in two regions.
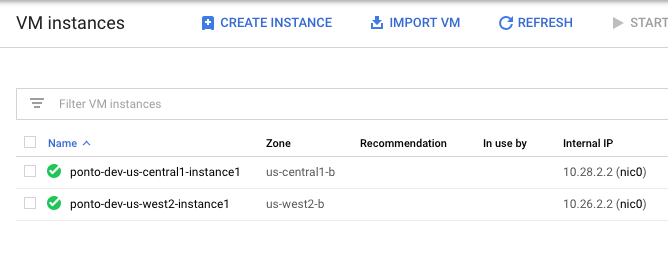
Also, two instances are created in two regions. At this point you can SSH to one instance and access the other.
You can delete this environment with:
$> terraform destroy
Summary
There aren’t as many examples of setting up a GCP environment with TerraForm. So initially, I had some issues and was a bit skeptical as to how well TerraForm would work with GCP.
Once I got the basics up and running though, I was pleasantly surprised by how well it worked, and also how fast GCP created resources and spinned up instances.
These TerraForm scripts also allow you to create a completely separate clone VPC with a mere command line argument. You can now build dev, test, integration or production environments with ease.
All this, of course, is possible if you start off your project with an automated build of the cloud environment.
I added a page on online Courses I completed to date. I discovered Coursera a few years ago. Coursera offers learning materials offered by some of the top universities around the world.
First courses I took were on things like Machine Learning, Probabilistic Graph Modeling. They were absolutely fascinating to me. And I was hooked.
So I started taking these online courses not just on Coursera, but wherever I could find an interesting topic. I took Apache Spark from edX, CUDA programming from Udacity, DataScience from DataCamp Cloud Computing on Qwiklabs.
I took courses on DataScience and Machine Learning mostly, but I also took courses on things like FPGA design and even songwriting.
Four Take-Aways
At this point, I have taken over 50 courses, so there are few things I learned about taking these courses.
First, although you can take most of these courses for free, I chose to pay to get certificates for most of them. Each certificate is not terribly expensive. They do add up to a fair amount if you get enough of them like I did. I think it’s still worth the expense because paying for and working for a certificate requires a higher level of commitment.
Second, these courses let you proceed at your own pace, and I took full advantage of that. And by that, I don’t mean go slow at your own pace. Instead, I go as fast as I can. I often finish courses in half the time, and I usually take a couple of courses in parallel.
Thirdly, and this is in relation to the previous point. I had to develop my own system to sustain this online course learning rate. I had to get better at organizing my time and more importantly, my attention and focus. You cannot absorb all this information if multi-tasking or constantly being interrupted.
I also settled on my own note-taking method where I take notes on a notepad (A5 grid from Rhodia or Nemosyne works best) then summarize formally into a notebook (Seven Seas Crossfield from www.nanamipaper.com – the best notebook and paper ever)
Lastly, I had to be clear about my goals. I didn’t want to just rack up courses. I wanted to learn as much as I can, but it also has to provide value. For that, knowledge and skill have to stick. It made me think about how best to approach the topic with clear end picture in mind. This last point is perhaps the most important thing I learned from all this.
Yes, I pretty much abandoned this site for a few years.
I’m pretty sure I had a good reason why at the time, and I have a feeling no one really missed me not updating this site since I didn’t have much content.
My bad.
Yes, I’m starting this up again, hopefully with a bit more consistency.
Fat finger is a real common problem. A lot of data that comes into analytics and reporting are often data entry originated. This means the data contains typos. And lots of them.
For example, people with strange long names will often show up in multiple data tables with different spelling because some data entry clerk somewhere just couldn’t get the name right.
Same or Kind of Same?
To solve this problem, there are algorithms to calculate how different two strings are. Levenshtein is one such algorithm. It calculates how much edit it takes from one string to get to another.
This works well on typos where you mistype a couple of letters, or even accidentally adding or deleting a couple of characters. Levenshtein correctly calculates how many edits, and you can apply a threshold and decide what is and isn’t a typo.
Unspeakable Typos
Levenshtein works well on regular words, but what about codes? Codes, such as part numbers or model numbers are frequently mis-typed because they are non-sensical to humans.
Considering how Levenshtein works, seems that it should work equally well on mis-typed codes. But what about the nature of mistakes themselves? People can mistype a letter or two in a word, but is it the same kind of mistakes people make when typing in alpha numeric codes? Do they make a couple of characters worth of mistakes, or do they make a whole lot in a field? Would Levenshtein sitll work in these cases?
VIN Problem
I recently ran into such a problem with Vehicle Identification Number (VIN). VIN is a unique number assigned to every car sold since 1954 in US. Today, it is used to identify any vehicle – well, almost any vehicle since cars sold in some countries do not have VIN’s. (surprisingly, Japan)
What I had was two sets of data containing VINs. They were supposedly the same dataset with same VINs, but many VIN’s did not match between the two.
The reason for the mismatch was because VINs were corrected. First table had original entries that contained mistakes. Second table had the mistakes corrected.
I needed data from both VIN was really the only way to uniquely identify the vehicle. What we had was a two table join, except that field used to join was edited on one table. Consequently, I ended up with a lot less records after the join. The edited records were dropped because VIN’s didn’t match exactly.
Levenshtein to the Rescue
So we figured if we calculated Levenshtein distance between two VINs and if they are lower than certain threshold, they are likely the same VIN.
We tested this out by taking some rows from first set, and blindingly calculated VIN Levenshtein against each and every VIN from another set.
Turns out, Levenshtein distribution was either >13 (entirely different) or <5 (pretty close). There was nothing in between. With this, I was able to match every single VIN to the other table.
Fat Fingering VIN
We then analyzed the fat-finger patterns of these VINs closely. As it turns out, people entering these codes are pretty careful. Common pattern was that they just missed one character, usually a number. People often mis-read 0, 8, 9 and 6 because apparently they looked similar. Worst distance was caused by a VIN that had 5 zeros and nines that were switched with nines and zeros instead.
The thing to note is that the nature of the mistakes and the data content was such that mistakes didn’t result in multiple-proximity. If you have a lot of similar codes that are close to each other, a mis-typed code can have similar Levenshtein distance to many of these codes. In this case, we would have to find another way or additional qualifier to match.
Still, Levenshtein or a similar algorithm should be evaluated for cleansing manually entered code fields like VINs.
Applying MapReduce
In this case, we calculated Levenshtein distances between every entry of large set against every entry of another large set, because we were concerned about multiple-proximity. Running such an nested loop comparison can be time consuming if the data sets are large.
For this study, we coded a quick MapReduce on Hadoop that calculates Levenshtein of an entry against every entry in the other set, to run this in an Embarrasingly Parallel manner.
This is basically doing a join where the join operator is (Levenshtein Value < threshold). As awkward as joins are in Hadoop MapReduce, joining on some arbitrary calculated value is quite powerful.
And performance was actually quite good. Even though we only had 10 Map tasks running in parallell on our petite Hadoop cluster, this was the same as executing 10 inner loops in parallel.
As far as we are concerned, there are two kinds of passwords. Strong and weak.
These days, you have all this password policy to enforce strong password. Not only do you have to have passwords longer than gazillion characters, you have to have mixed case, numerics and even a Cyrillic character or two just so that password is strong enough.
And then there are weak passwords. Not only are they weak, they are often backdoor passwords. It may be for a database or for IT to do admin tasks, but weak backdoor passwords always exist. So many people depend on that password that you can’t change it without having a lot of people upset, or even halting some important application or production process. Backdoor passwords are weak, easy to remember and hardly ever get changed.
Lost Passwords
You will invariably run into lost password. Just the other day, I completely forgot a password to a WebDAV server I set up not too long ago. I could set a new password, but I have to go change all these machines and handheld devices that are dependent on this WebDAV server. This can easily take 30 minutes to an hour. Life would be easy if I can just recover that one password.
Cracking Your Password
Is there a way to recover lost password? You know them IT guys will always tell you no. This is true, in that they can’t see what your passwords are. Systems are built that way. But can’t you *really* recover a password?
Well actually there is. A password is encrypted and stored as a hash. And given this hash, there are software that can decrypt this password.
Now, these software isn’t some shady crack software intended to be used for breaking into people’s system. It does have a legitimate use such as, well, retrieving password or finding weak passwords that are easily decrypted.
So I fed the encrypted password value for my WebDAV server into this software and let it run. Sure, it might take a day or two, but I can wait.
But to my amazement, it spat out the password after only 24 minutes of churning at it. Only 24 minutes? That’s less than the amount of time it takes to change the password on all the places that uses it.
Lessons Learned
What this means is that passwords are not as secure as one might think. And you need to do something about it:
Don’t use weak passwords. More scrambled the password, the longer it takes to decrypt. This also means don’t use your first name, your SS, your phone #, dog’s name, kid’s name, etc. etc. Yes, all the stuff you’ve been told is really true.
If you are a conscientious IT expert, be proactive and try decrypting passwords from hashes. Get the most security critical password hashes out of Databases or password files and run them through decryption. How easily these passwords are cracked will shock you, and should prompt you to take an action.
But most importantly,
Don’t expose the password hash. Encrypted may be, but they are still passwords. You are essentially giving your accesses away when you leave your encrypted passwords out in the open.
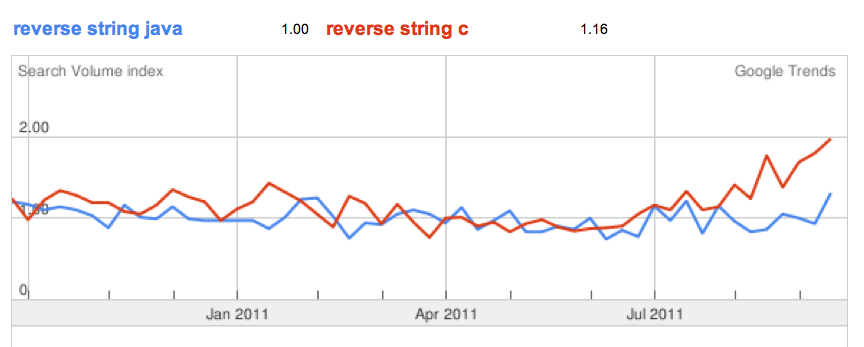
Reversing a string is a pretty common interview question.
I can’t recall ever having to reverse a single damn string in my programming career, so it’s probably safe to say string reversal is very specific to job interviews.
That may make it seem useless, but it is a realistic use case that any upwardly mobile programmer like yourselves will eventually run into.
So let’s think about this a little bit.
How would we go about figuring out how to reverse strings in preparation for an interview? Well, it goes something like this for most people:
In C – Google for an answer
In C++ – Google for an answer
In Java – Google for an answer
Seriously, this really is what people do, and here is what Google Trends shows to back it up.
Now before coding purists denounce this whole string reversal exercise as stupid and waste of time, let’s dig this down a little further.
The string reversal question takes on a different context given that it’s an interview question. I mean, everyone comes to the interview after looking up the same damn answer. So why ask this question?
I for one, don’t care if a candidate looked up the answer on the Internet. Actually, I don’t care if you know how to reverse a string at all.
If I ask the string reversal question, that’s because I am looking for traits. Is this person a copypaste monkey who just looks things up and try them all till something works? Is there any logical thinking, adaptation or creativity involved?
After all, the whole purpose is to see if the person is capable of turning knowledge into skill and expertise that we, the team, can turn to.
So if I ever asked a string reversal question, it’s not because I want to know if you know how. It’s really because I want to know what you are made of.
Getting a count of occurrence is common. A real world example would be Apache log. We often want a list of all IP addresses and their occurrences in this log. This would tell us how many accesses were made by this IP address.
This kind of aggregation is a pretty common thing. It keeps coming up often enough that we decided we should find the most efficient way to do this.
We took a 3GB httpd log with 12 million lines from a real production web server and processed it several ways.
RDBMS vs Hadoop
We first loaded the data into an RDBMS. Well, we tried to, anyways. This literally took forever despite loading 10000 rows per transaction. It wasn’t done after 90 minutes so we cancelled.
Then we tried it with Hadoop. We set up a 3 node Hadoop cluster and ran a simple Map/Reduce Java code. It took 2 minutes to copy 3GB file into HDFS, and another 3.5 minutes to Map Reduce to get the output we want.
To be fair, with smaller data set, RDBMS has been able to deliver this query result in seconds. But that’s only after the data is loaded and indexes are built. That’s a lot of work for ad-hoc query. End to end time is much quicker with Hadoop.
Then There’s Awk
With all that said and done, we don’t use RDBMS or Hadoop if we want simple column aggregation on a delimited text file less than 10GB. We use this one liner from a shell command line:
This is a place where we will post our tech notes and impressions as we work with various technologies.
Many content here will no doubt be yet-another-‘how to install XXX’ notes, which can be of use to those who are looking for such specific information.
More importantly, though, we are going to take notes on things that are more tangible. We aren’t just going to jolt down how we installed and ran some Software, we will try to see how it applied to solving some real world problem at hand.
And in that sense, hopefully the content here will have a uniqueness and usefulness of its own.